How Hashing Works | Deeper Look
Hashing is a very important topic in today’s computer science. And it is becoming more and more important. Databases are based on it and logins become more secure. But what exactly is a hash and why is it so important?
What is a hash?
The name “hash” comes from the verb “to hash” and means “to chop up” or “to chop small”.
And this is exactly what a hash function does. It maps a larger, arbitrarily large input set into a smaller target set. The input set is chopped into small parts, which then form the target set, which is called a hash. But it is not as simple as it sounds.
A hash consists of a subset of the natural numbers which are then represented as a hexadecimal number.
Example for a hash:
This is a hash --(MD5)-> 5d59d36569272e0f4e11dea9b2b2e756
These are the requirements for a hash algorithm:
- In a hash function, the same input should always result in the same output. Therefore, random elements must not be used in the computation of a hash function.
- At the smallest change of the input the output must change drastically. In this way, changes to the input can be seen immediately.
- The hash algorithm should consider the whole input to generate an output.
- It should not deliver the same output for N different inputs. Hard is to keep N as small as possible. (collisions)
The last point is especially important in cryptography, because this could be a possible point of attack.
Often a hash value is also called a fingerprint, because it makes it easy to identify a file of any size. Comparable to the fingerprint of a human being.
Difference between encryption and hashing
It is important to know the difference between hashing and encrypting. Often both are thought to be the same thing, which is not quite true.
Encryption assumes that the encrypted information can be decrypted again using the correct key.
As an example: Bob sends encrypted information to Alice. However, this information can only be made readable again by using the correct key.
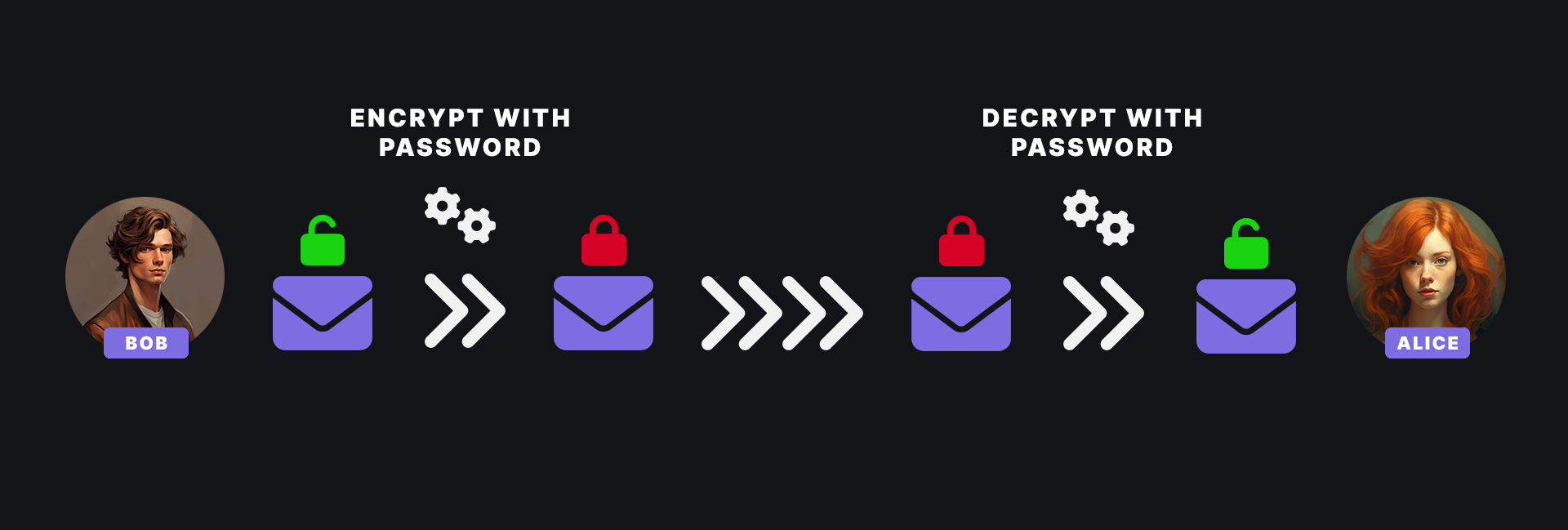
With a hash function, however, the original information cannot be made readable again. This is then called a one-way function.

How does hashing work?
For most people (also programmers sometimes) a hash function is a black box. You use it every day, but most of the time you have no idea how it works. In the following section it will be explained as understandable as possible what a hash algorithm does exactly with the single bits. However, it should be noted that this does not apply to all algorithms, as they are constantly being developed further to withstand attacks. There are many different ways a hash algorithm can form a hash. Here is an explanation of one of them.
Starting point
Let’s take any bit sequence with a length of L (L here stands for any length). That means, there are \(2^L\) possibilities how the bit sequence could look like (One bit has state 0 or 1).
Objective
Now the bit sequence with length L is to be converted into a previously defined length S of bits.
Algorithm
Each bit L is started to be assigned to a bit of S. When the end of S is reached, it starts again from the beginning and each bit changes its value (1 becomes 0 and 0 becomes 1) if it has to be filled a second time. This is repeated until the end of L is reached.
L = 01010100 01100101 01111000 01110100 ("Text")
S = A length of 8 Bits
Step 1, all bits of S are filled once:
S = 01010100
Step 2, invert all bits of S:
2.1. -> S = 01010100 // S with the bits of L
2.2. -> S = 10101011 // Inverting the bits of S because of "01100101"
2.3. -> S = 01010100 // Inverting the bits of S because of "01111000"
2.4. -> S = 10101011 // Inverting the bits of S because of "01110100"
S = 10101011 (Binary) = 171 (Decimal) = AB (Hexadecimal)
Endhash = AB
Problem
However, there is a problem with this algorithm. If the person who wants to modify/manipulate the file is smart enough to figure out which bit belongs to which bit in the original bit sequence, they can modify the file in such a way that it would not be noticed.
Possible solution
There are two ways to prevent this. The first one is to encrypt. The only difference is that the encryption key is larger than the bit sequence L. This can then be repeated as often as needed until the final hash is correct.
The second consists of using multiple mixing algorithms. With a mixing algorithm a so-called seed can be given. Depending on the seed, the algorithm behaves / mixes differently. Now packets of eight are formed from the bits of L (thus always 1 byte). Now the previously obtained hash is mixed for each packet (byte). The seed is thereby the byte (the 8 bits).
Attention: shuffling algorithms have not been used realistically in the example below. They are only used for demonstration purposes and are chosen randomly.
S = 10101011 // The Original-Hash
S1 = 10010101 // 10101011 mixed with the first byte (01010100)
S2 = 00101010 // 10010101 mixed with the second byte (01100101)
S3 = 11010100 // 00101010 mixed with the third byte (01111000)
S4 = 00010010 // 11010100 mixed with the fourth byte (01110100)
End-Hash = 00010010 (Binary) = 12 (Hexadecimal)
The challenge with the algorithm is to program it in such a way that completely different results are output for the smallest changes.
Where are hashes used?
Hashes can be found in many different areas of computer science.
Databases
For example in databases. With the help of so-called hash tables, databases can search and retrieve stored data in large data sets quickly and efficiently.
Checksums / Data transfer
A hash can also verify and guarantee the integrity of a file. This is especially recommended for downloads from third party sources or for critical data of users, because a change of the file would be noticed immediately. If the hash does not match that of the original, it can be assumed that the file has been manipulated.
Hash values are also an important component of P2P (peer-to-peer) applications. There they are used to search for and identify files as well as to recognize and check transferred file fragments. In this way, large files can be reliably exchanged in small segments. To make this possible, staged hash functions are primarily used, in which the hash value is calculated for the small parts of a file and then an overall value is calculated from these values.
Various backup applications also benefit from hashing. Changes can be easily detected by hashing, so that the data to be backed up can be backed up.
Cryptology
Storing passwords in plain text is considered very insecure and can put many Internet users’ passwords at risk in the event of a successful hacker attack on, for example, a database. To store them securely, special cryptographic hash functions are used. These are more complex to calculate and should make a brute force attack more inefficient.
About hackers and rainbow tables
Since secure password storage was briefly written about above, I would like to discuss cracking hashed passwords here.
It should be noted that this method only works if the hacker has already obtained the hashed password.
If this has happened, the hacker usually performs a so-called rainbow table attack. The rainbow table is a data structure developed by Philippe Oechslin that allows a fast and memory-efficient search for an original string (usually the password) of a given hash.
This allows the attacker to search for the hash value in a previously generated table (the rainbow table). If the password was not chosen to be too complicated, the password may be present in the Rainbow Table. An example of a rainbow table would be crackstation.net. The MD5 hash for “Hello World” was found within 2 seconds (please note that MD5 is considered insecure).
If you want to test yourself if your password is secure enough, you can hash your password with e.g. SHA256 and enter the hash at crackstation.net. If it is found, you should think about the strength of your password. However, even if your password is not found, there may be a Rainbow table on the Internet with a larger size containing your password.
Brute-Force vs. Rainbow-Tables
Since a rainbow table allows a much faster search than a brute force attack, but at the same time requires more memory to store all the hashes and the corresponding plaintext, it is usually a matter of weighing which of the two attacks comes into play.
The attack
The prerequisite for a rainbow table attack is a hash without salt (additional text appended to the password). A good example for this are earlier Windows versions or various routers still in use today.
Security measures
But how do you protect yourself against such an attack? It was mentioned above that such an attack requires a hash without salt. Here is a short definition of a salt (cryptography) from Wikipedia:
In cryptography, a salt is random data that is used as an additional input to a one-way function that hashes data, a password or passphrase. Salts are used to safeguard passwords in storage.
- SALT (CRYPTOGRAPHY), WIKIPEDIA
That is, if I append a random salt (e.g. “4ef670ac320”) to my password (e.g. “test”), the hash (almost) cannot be found by a Rainbow table. Because for this the rainbow table would have to contain the value “test4ef670ac320”, which is very unlikely with a random string as salt. This means that the longer the salt, the less likely it is that the hash will be cracked.
But a salt is not the only way to make passwords more secure. If the hacker could not gain access to the hash, he will probably try a brute force attack. With this one, speed is crucial and can make the difference between success and defeat. If an attempt takes just 200 milliseconds longer, a few days, can quickly turn into a few months or years (Depending on the strength of the password). To implement this, you can include a wait time for each attempt of a password request. The user will not notice the difference as of 200 milliseconds longer login time is almost unnoticeable.
Alternatively you can realize this with a work factor. This means that the password is hashed several times in a row to get a still secure hash. The process for the hash then also takes longer and will cost the attacker more time.
Insecure hash functions
Some hash algorithms are now considered insecure or cracked. Among them are
- MD2
- MD4
- MD5
- SHA-1
- GOST
- Snefru
- Panama
- LM Hashes
- LAN Manager
- Message Authenticator Algorithm
These algorithms should no longer be used for hashing passwords, since very extensive Rainbow tables already exist for them from various sources.
However, it is only a matter of time before the next Rainbow tables for today’s secure hash algorithms are published. Google has already cracked the hash procedure SHA-1, which was previously considered secure, by creating a collision.
Conclusion
Hashing and hash values are an important part of today’s computer science. If hash functions were to suddenly fail, the consequences would likely be catastrophic.
The most important things about a hash function are:
- It cannot be inferred from the output to the input
- Must not be random (same input = same output)
- Collisions are to be avoided if possible
Hashing is important to store passwords securely, so that passwords are difficult to crack in case of a hacker attack.
Hash functions are complicated and is not everyone’s favorite topic. However, we can be happy that someone developed it and makes our passwords a bit more secure.